正規化とはデータを扱いやすくするために行う「データベース設計の手法」です。
データベースは常にレコードが追加され更新され、また削除され続けます。もし正規化を適切に行っていなければ、データベースの中でレコード間で矛盾が発生し、データベースとして役割を果たさなくなってしまいます。
簡単に言えば、正規化の目的はデータの重複や不要な依存関係を排除することです。これにより、データの整合性を維持しやすくなります。
このページでは、データベース初心者向けに(もしくは、何度か正規化について学習しているけれどいまいち理解しきれない・・・という方向けに)データベース正規化の目的や、正規化の手順、基本となる知識をわかりやすく網羅的に解説します。
前提となる知識もこのページで網羅的に解説していくので、専門用語がわからない・・・という方でもご安心ください。
データベースエンジニアを目指す方はもちろん、システムエンジニアやプログラマーを目指す方であれば知らないと恥ずかしい超・基本知識です。
是非最後までご覧ください。
正規化とは?
正規化(英:Normalization)の最大の目的は、データベース上で扱うデータの重複を削除し、データの更新時に発生する異常を取り除くことです。
データベースには常に更新が発生します。正規化を適切に行っていない場合、レコードの更新時に異常が発生し、正しくレコードが登録されなくなってしまいます。
最初に "正規化されていないデータベース" にはどんなリスクが潜んでいるのか?を簡単にご説明します。
正規化をわかりやすく
「正規化できていない」以下2つのテーブルを考えます。
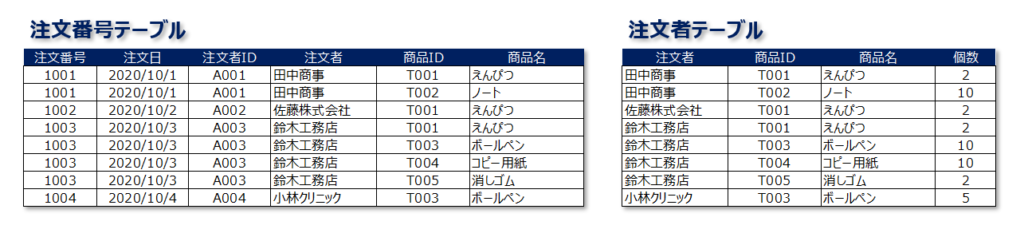
左側のテーブルは注文を受けたらその内容をどんどん追加していくようなテーブルで、右側のテーブルは注文した人とその内容を整理して出来上がったようなテーブルです。
一見、2つのテーブルはちゃんと利用できるように思えます。ですが、実はこのテーブルは利用しているとレコード間の不整合が発生します。
例として、このとき注文がキャンセルされてしまい、注文番号テーブルから対象のレコードを削除するとどうなるか?を考えてみたいと思います。
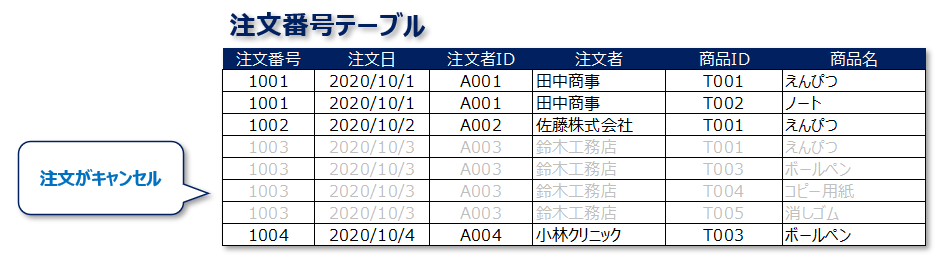
もし、キャンセルを受けた担当が、上記4つのレコード「だけ」削除してしまうと、テーブル間での矛盾が発生します。
本来であれば、4つのレコードを削除すると同時に、注文者テーブルの方のレコードも同じように削除しておく必要があります。
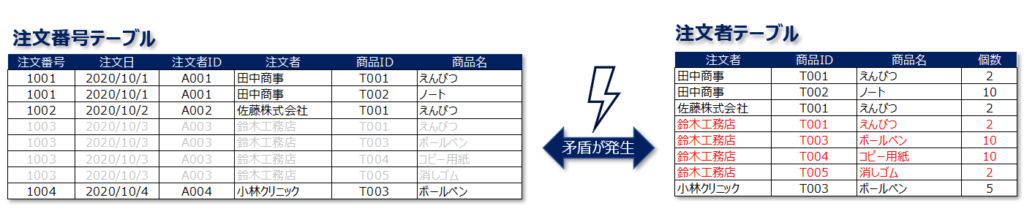
「注文番号テーブル」には存在しないのに、「注文者テーブル」にはそれに対応するレコードが存在するという謎な現象が起きてしまうのです。
このように正規化されていないテーブルを扱おうとすると、テーブル間の不整合が起きたり、レコードが破損してしまうなど、どこかで異常が発生することは避けられないということが分かります。
ここでは非常に簡単な例で説明しましたが、これだけではなく様々なパターンの更新時異常が存在します。
正規化しなくても、毎回必ず両方のテーブルを更新するようにすればOKなのでは?という疑問が出てきますよね。
結論から言えば、ある意味では「その通り」です。
例えば、更新時に異常が発生しないように更新が必要なすべてのテーブルをプログラムで更新するようにしたり、マニュアルを用意して片方のテーブルを更新したらもう一方のテーブルも更新するようにしたり・・・などの案が考えられます。
が、いずれにせよプログラムをきちんと作りこむ必要性やマニュアルの作成など、別のコストが発生してしまうことには変わりありません。また、通常そのような無理な回避策は長年動くシステムや業務では必ず破綻していきます。
したがって、あらかじめデータベースの正規化を適切に行っておく方がGood!な判断である場合がほとんどです。
正規化の手順
では、正規化はどのように行うのか?ここからは具体的に正規化とは何か?その手順はどのように進めるのか?をご説明していきます。
データベースの正規化は以下の通り順を追って進められます。
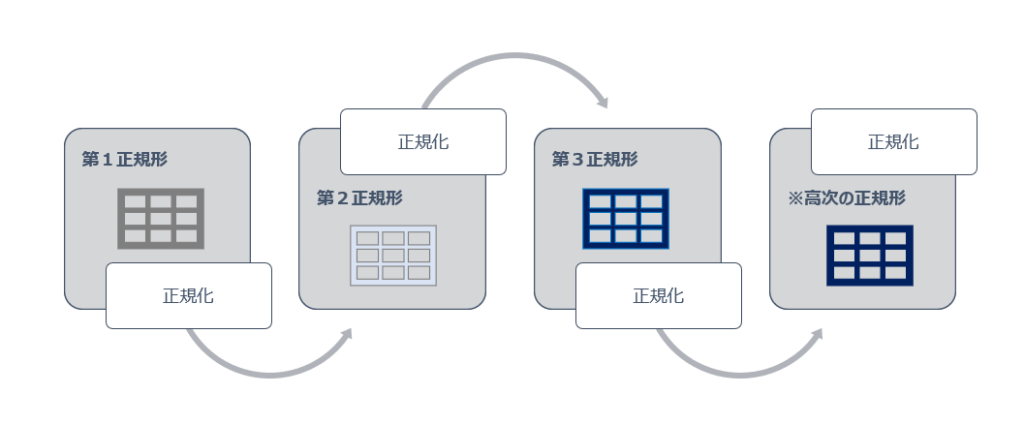
上記図の通り、正規化の過程ではデータベースはいくつかの「正規形」(例:第1正規形 / 第2正規形~)を経て構築されます。以下は正規化の主要な手順を簡単に説明したものです。
- 第1正規形 (1NF)
- 各カラムに1つの値のみを持たせる。
- 同じカラム内での重複を避ける。
- 第2正規形 (2NF)
- 合成キー(2つ以上のカラムの組み合わせ)を持つテーブルで、キーの一部のみに依存するカラムを分離する。
- 第3正規形 (3NF)
- ある非キーカラムが他の非キーカラムに依存している場合、その依存関係を排除する。
- 高次の正規形
- 3NFを超える正規形(BCNF、4NF、5NFなど)も存在しますが、実際のデータベース設計でこれらを厳密に適用することは珍しい→しかし、特定の問題を解決するためにこれらの正規形を考慮することは有益。
正規化は一気に終わるのではなく、順を追って徐々により高次な正規形に進化していくようなイメージを持てればまずはOKです。
また、上記では現在存在する正規化の手順をすべて記載しましたが、実際のところは「第1正規形~第3正規形」までが基本で、それより高次の正規化は大抵の場合は不要。
理由はページ後半でまた解説しますが、まずは第1正規形~第3正規形を確実に理解することを目標としてください。
それでは実際の正規化の手順を順を追ってご説明していきます。
第1正規形
第1正規形の定義は、わかりやすく説明するとExcelのような1セル1レコードのテーブルとして表現できるようにすることです。
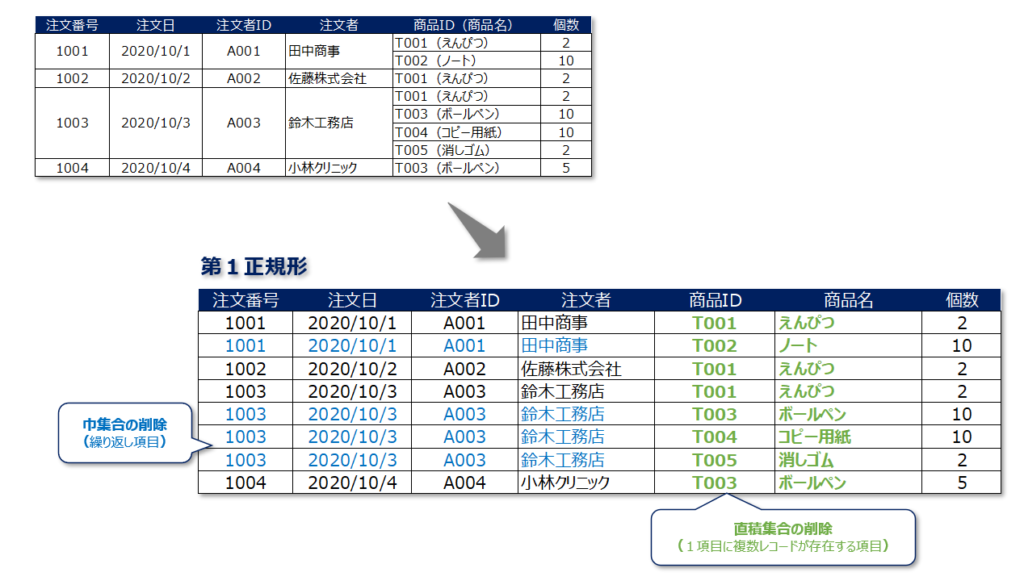
第1正規形はご覧の通り超・単純です。
正式にはすべてのドメインがシンプルであること(=1セル1レコード)というのが第1正規形の定義です。
具体的には①:繰り返し項目を取り除くこと、②:2つ以上のレコードが保存されているドメインを取り除くこと、の2つが一番初めにおこなう正規化です。
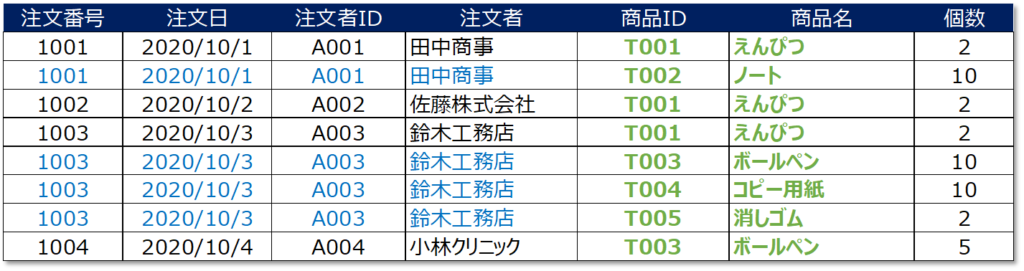
以下のテーブルを例にすると青字部分は繰り返し項目・緑字部分が1つのドメインに2つのレコードが存在(商品IDと商品名)しているので、第1の正規化対象です。
これらの項目を整理して出来上がるテーブルが第1正規形です。
第2正規形
続いて第2正規形の説明です。ここからグッと専門用語が多くなり、難易度も上がります。
多くの人はこの第2正規形の説明でドロップダウンしてしまうので、ゆっくり確実に学習を進めていきましょう。
第2正規形は「テーブルの各候補キーに従属する部分関数従属性が整理された」状態です。
「候補キー」「部分関数従属」の2点について用語の意味をご説明します。
候補キーとは「レコードを一意に特定するための属性(=カラム)」または「レコードを一意に特定するための属性の組み合わせ」です。
例えば、以下のテーブルであれば候補キーは「出席番号」です。
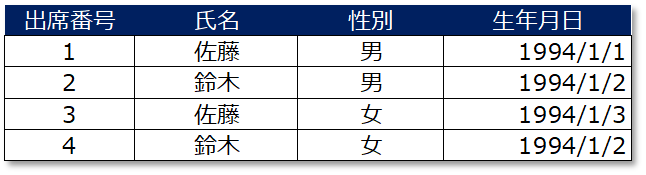
出席番号さえ分かれば、どのレコードを指し示しているかが分かりますよね。
したがって、上記のテーブルでは出席番号項目が候補キーであるといえます。
逆に「氏名」列や「生年月日」列は同じ値が存在する可能性もあるため、候補キーとは言えません。
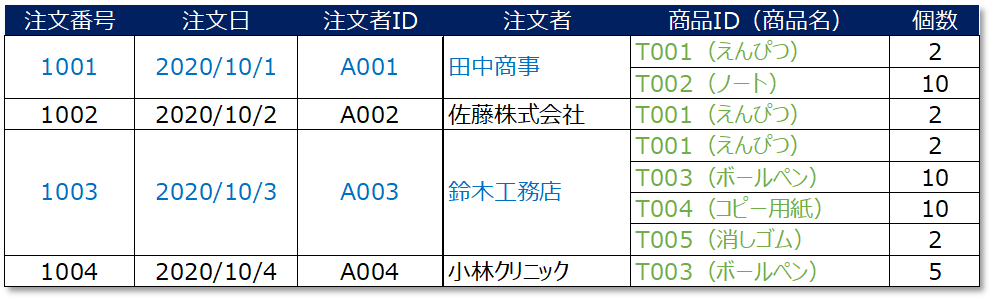
では、先ほど第1正規形を行ったテーブルの候補キーはどれになるでしょうか?
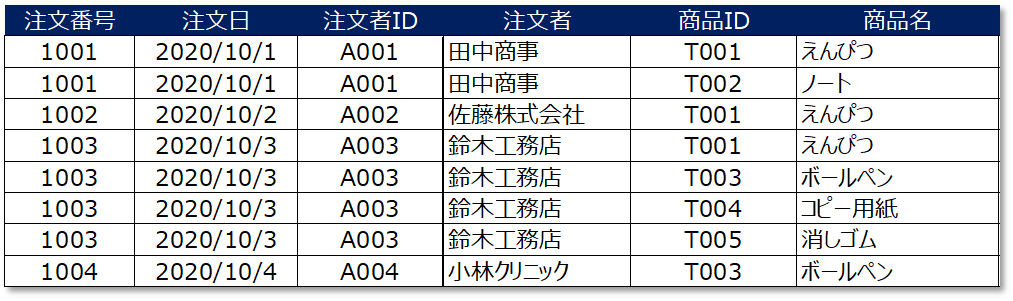
この場合は、どの列も単独ではレコードを一意に特定することができません。「注文番号」も「注文者」などが候補キーに該当しそうな気もしますが、どちらの列にも同じ値が存在します。
この場合、1つの項目が単独でレコードを特定することができないため、候補キーは各項目の組み合わせを判断し特定する必要があります。
上記テーブルの場合は "注文番号" と "商品ID" が分かれば("注文番号" と "商品ID" の組み合わせを見れば)、どのレコードを指し示しているかを特定することができます。
したがって、候補キーは "注文番号" と "商品ID" になります。

また、重要なポイントの1つが「候補キーは複数存在する可能性がある」ということです。例えば、上記のテーブルでは「注文番号」と「商品名」の組み合わせも、候補キーになります。
何故なら、注文番号と商品名が分かれば、先ほどと同様にどのレコードを指し示しているかが分かるためです。
したがって、上記テーブルの候補キーは(注文番号,商品ID)と(注文番号,商品名)ということになります。
部分関数従属とは「一部の候補キーに対して」関数従属する属性を言います。
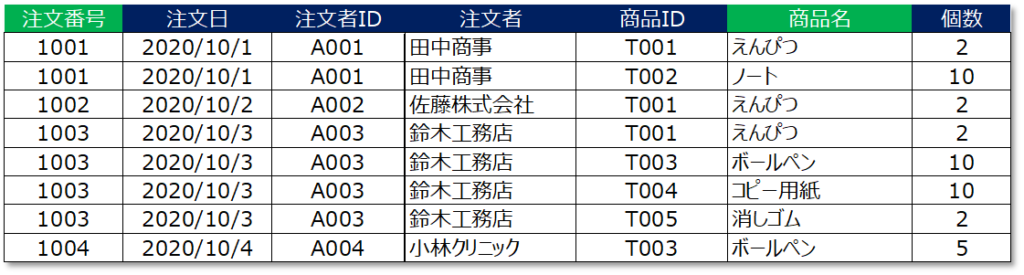
例えば、以下のテーブルでは注文番号が決まれば「注文日」「注文者ID」「注文者」のカラムは一意に決定することが分かります。
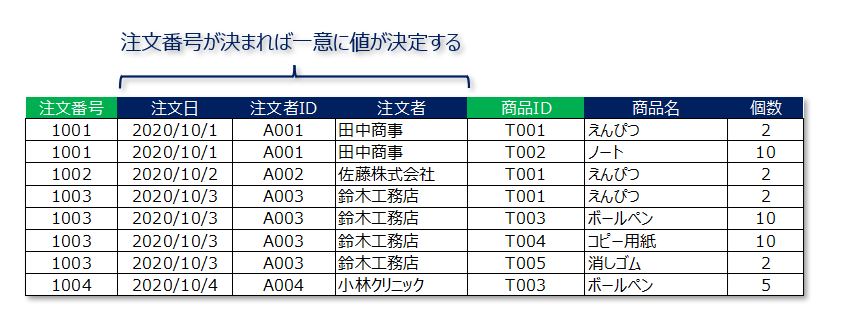
注文番号が「1001」であれば必ず注文日は「2020/10/1」で注文者IDは「A001」、注文者は「田中商事」に確定します。
このとき、注文日・注文者ID・注文者のカラムは候補キーの1つである「注文番号」に関数従属しているため「部分関数従属」している、ということができます。
また、同じ原理で「商品名」も商品IDに対して部分関数従属しているということができます。
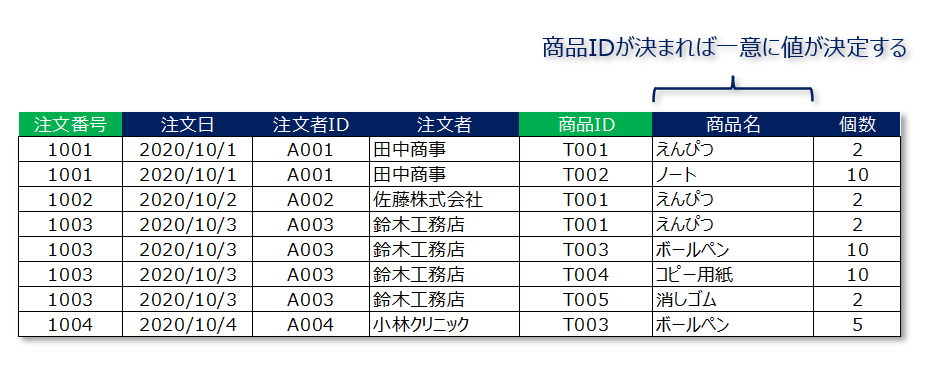
第2正規形は「テーブルの各候補キーに従属する部分関数従属性が整理された」状態です。
したがって、部分関数従属している列を切り離し別のテーブルとして整理するのが第2正規化の手順です。
初心者にとってはこの第2正規形が第1正規形~第3正規形の中で1番理解しづらい部分です。
一度読んで理解しきれなかった方はもう一度この章を学習しなおしておきましょう。
第2正規形が分かれば、第3正規形は実はそこまで難しくはありません。
第3正規形
第3正規形は候補キー以外の列に関数従属している列が整理された状態です。
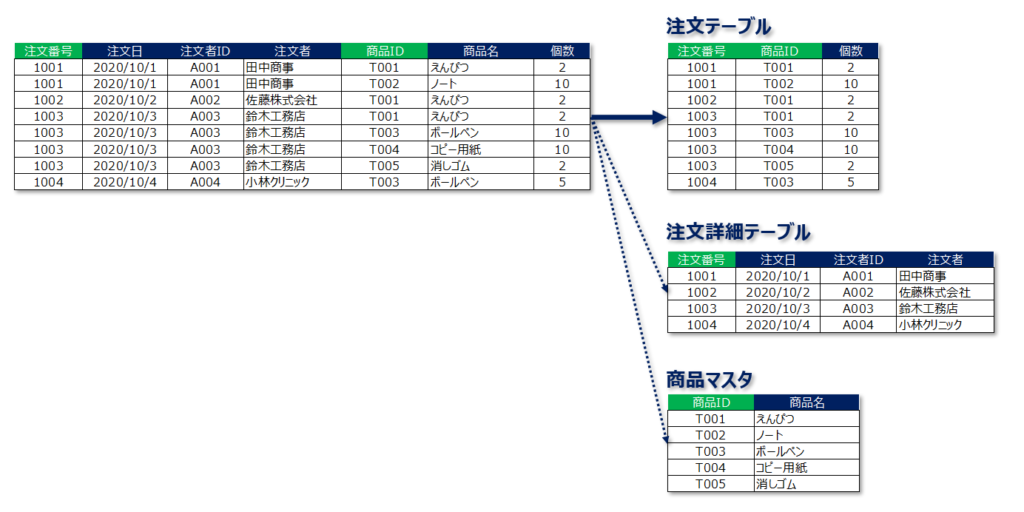
第2正規化で整理された注文詳細テーブルを例に第3正規化の手順を見ていきましょう。
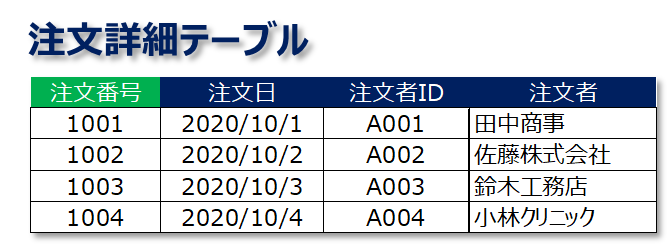
第3正規形は「候補キー以外の列に関数従属している列が存在しない」状態です。したがって、上記の例でいうと、候補キーではない注文者IDに関数従属している「注文者」列を別表に移すのが第3正規化で行う手順です。
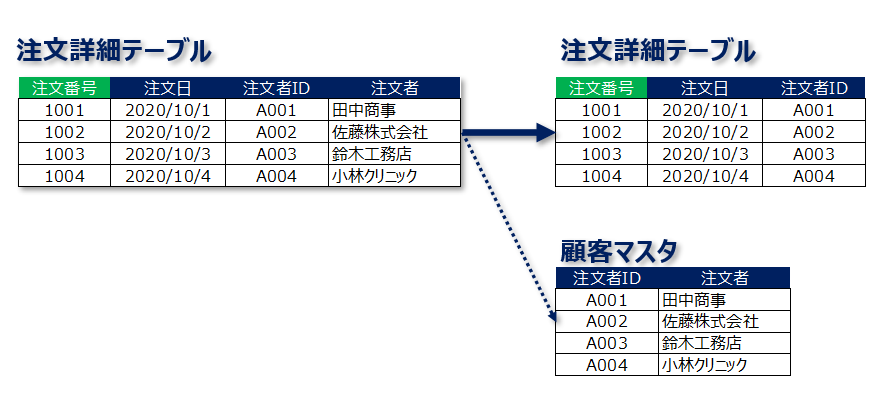
"注文者" 列を注文詳細テーブルから切り離し顧客マスタとして独立させました。
これによって、候補キー以外の列に関数従属している列が存在しない状態を作り出すことができます。
当初1つのテーブルに存在していたデータが正規化を行うことで、以下の4つのテーブルに整理されました。
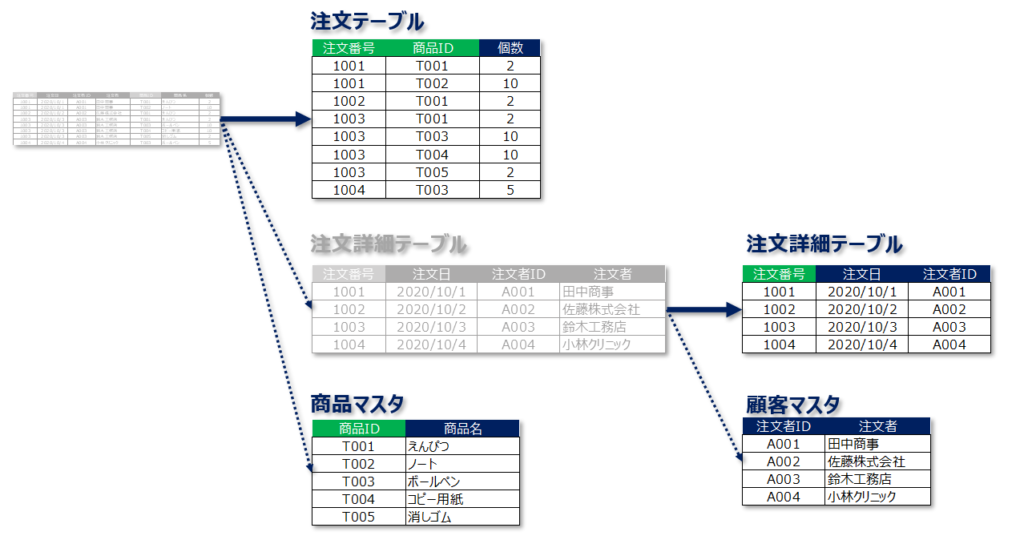
この4つのテーブルが以下の第1正規形~第3正規形までの定義を満たしていることを確認してみてください。
システムエンジニアを目指したい方は
システムエンジニアを目指す方や、IT知識を1から身につけたい方は以下のページをご覧ください。
正直どこから学び始めればよいかわからない。どのように勉強していけば、エンジニアとしてのスキルが磨けるか?が分からない・・・という方は必見です。
システムエンジニア向けに「できるエンジニア」になる方法を1から解説しておりますので、是非ご覧ください。
