
インデックス(index)とは、テーブルの特定の列に対して作成されたデータ構造で、データの検索や並び替えを高速化するために利用されるデータベース管理の仕組みの1つです。
わかりやすく説明すると、辞書の 「目次」 のようなものです。

特定の単語を調べたいときに辞書の1ページ目から探そうとするよりも、目次から辿った方が早いですよね。この「目次」と同じような働きをするのがインデックスです。
インデックスを正しく適用することで、対象のテーブルは検索スピードが向上。大量のデータが保存されている場合でも素早く結果を取得することができるようになります。
このページではインデックスの仕組みを1からわかりやすくIT初心者向けに解説します。
システムエンジニアを目指す方であれば知らないと恥ずかしい超・重要知識です。是非最後までご覧ください。
インデックスとは?
インデックスとは、データベース内のテーブルの行を高速に検索するためのデータ構造です。
例として図書館の本を管理するデータベースを考えてみます。このデータベースには、データベースには「本のタイトル」「著者」「出版社」「出版年月日」などの情報が含まれているとします。
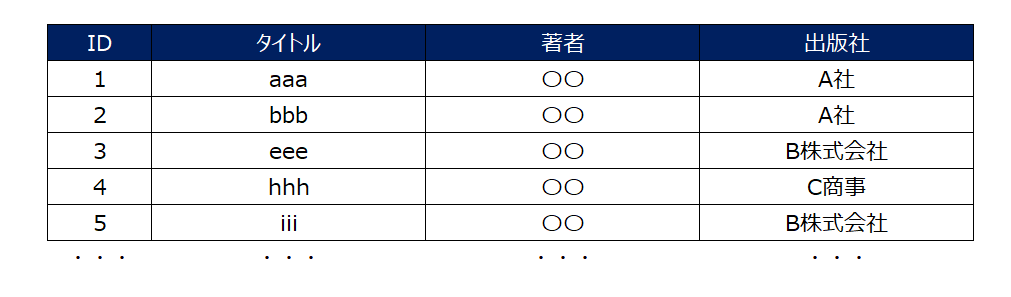
もし、あなたがこのデータベース内の「本のタイトル」を検索する場合、もしインデックスが存在していなければ、データベース内のすべての行を順番に検索する必要があります。
レコードの上から順番に地道に対象のレコード(=目的とする「本のタイトル」)を探していきます。
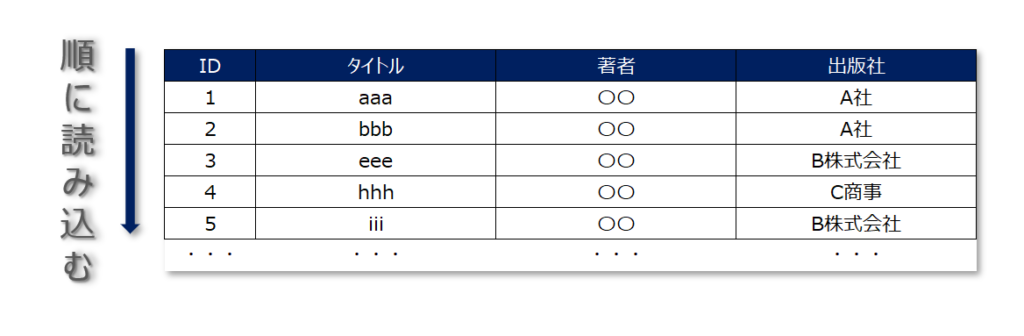
数千件程度のデータ量であればすぐに結果を取得することが可能でしょう。しかし、数億件のデータを扱うようなデータベースでは検索処理に膨大な時間を要します。
このとき、例えば以下のようなデータ構造のインデックスを考えてみます。ざっくりいうと「タイトル」と「そのタイトルの本のレコードが "何行目にあるか?" 」を整理したメモ帳のようなものだと考えてみてください。
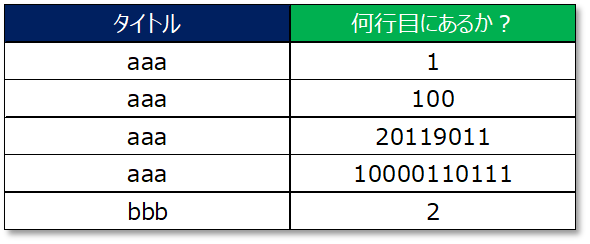
データベースはインデックスが存在する場合はテーブルに検索をかけるのではなく、まずはインデックスに対して検索を実行します。その後、インデックスから取得した情報に基づいて必要な行(=レコード)を探しにいくというような処理になります。
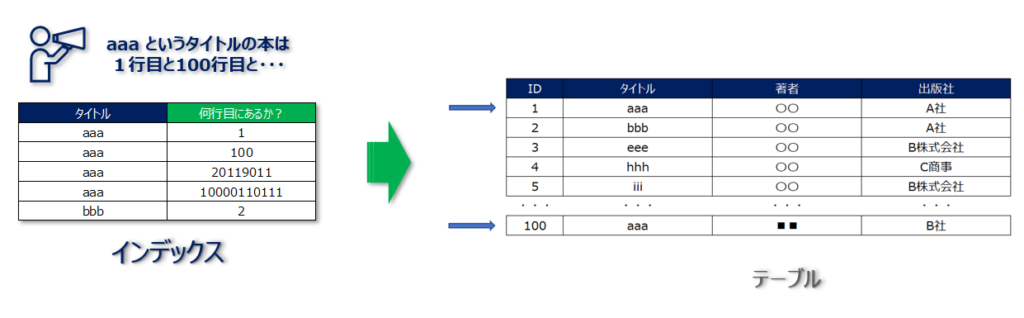
上記の例ではインデックスによれば、「aaa」というタイトルの本は1行目と100行目と・・・にあることがインデックスから判断できますよね。その後、実際にテーブルに検索をしにいくときに、インデックスから得た対象のレコード情報(1行目と100行目と・・・)を取得すればOKということになります。
以上のような流れで、インデックスを用いて大量のデータがあるテーブルに対して素早い検索を実行することが可能になります。
インデックスは「本のタイトル」のような重要な列を含む特定のテーブルの列に対して作成されます。(辞書も「単語」の頭文字に対して目次をつけるのと同じ考え方です。)
エンジニア向けのより具体例な例として、以下のようなテーブルを考えてみます。
CREATE TABLE Users ( id INT PRIMARY KEY, name VARCHAR(255), email VARCHAR(255), age INT );
参考:CREATE TABLE
このテーブルに100億件のユーザー情報が格納されているとします。
このテーブルを利用して、特定の条件に合致するユーザーを検索する場合(以下のようなSELECT文を実行する場合)を考えてみましょう。
SELECT * FROM Users WHERE name = 'John';
このSQL文を実行すると、name列が 'John' であるユーザーを検索しているためテーブル内の全ての行をスキャンする必要があります。つまり、1行目~1億行目までを順に検索(スキャン)していき、name列が 'John' に一致するレコードを取得します。
ですが、数億件以上のデータがある場合、このスキャンにかかる時間が長くなってしまい、パフォーマンスが低下します。
データ量が多くなれば多くなるほど、検索にかかる時間も比例していきます。
そのような場合に利用するのがインデックスです。この場合はname列にインデックスを作成することで検索の速度を高速化することができます。
name列にインデックスを作成するには以下のようなSQLを実行します。
CREATE INDEX idx_name ON Users (name);
このインデックスを作成すると、name列を利用した検索が高速化されます。
先ほどのSQL文を実行する場合、インデックスを読み込んでから実際のテーブルに検索を書けに行く処理になるので(=全ての行をスキャンする必要がなくなるので)、検索の速度が大幅に向上することが期待できるというわけです。
インデックスの作成方法
インデックスを作成するにはCREATE INDEX文を利用します。
CREATE INDEX インデックス名 ON テーブル名 (カラム名1, カラム名2,・・・・)
CREATE INDEX文の詳しい利用方法については以下の記事をご覧ください。

インデックスの種類
インデックスには利用するシーンや目的に応じていくつかの種類が存在します。
ここでは代表的なインデックスを5つほどご紹介します。
細かい内容までを頭に入れる必要はありません。ここでは、インデックスに対するイメージをより深めることを目的に学習していきましょう。
ユニークインデックス(Unique Index)
テーブル内のある列に対して一意の値を持つように制約を設定するためのインデックスです。
重複する値を持つことができないため、プライマリキーとして使用されることがあります。
プライマリキーインデックス(Primary Key Index)
テーブル内の主キー列に対して設定されるインデックスです。テーブル内のレコードを一意に識別するために使用されます。
参考 主キーとは?
クラスター化インデックス(Clustered Index)
テーブル内のデータを物理的に並び替えることで、データベースのパフォーマンスを向上させるためのインデックスです。特定の列に対して一つだけ作成することができます。
ノンクラスター化インデックス(Non-Clustered Index)
テーブル内のデータを物理的に並び替えず、インデックスによって検索を高速化するためのインデックスです。
特定の列に対して複数作成することができます。
ビットマップインデックス(Bitmap Index)
列内のデータがビット(0または1)で表現される場合に、検索条件に基づいて高速に検索を行うためのインデックスです。
頻繁に更新される列には適していませんが、列の値が少ない場合には高速な検索が可能です。
インデックス設定時の注意点・Tips
インデックスの良い面ばかりを説明してきましたが、必ずしも良い面ばかりではありません。インデックスの弱点を踏まえて、インデックス設定時の注意点を解説します。
1:頻繁に検索される列にインデックスを設定する
インデックスは検索の高速化が主な目的であるため、頻繁に検索される列に設定することが重要です。
一方で、あまり検索されない列に設定する場合、インデックスの効果が低下し、むしろパフォーマンスを低下させる可能性があります。
インデックスそれ自体もある種のデータであり、その分データベースの容量を圧迫する可能性が出てきます。したがって、プログラムからどのようなアクセスがあるのか?どのようにデータが読み込まれるのか?を把握し、適切な列(=カラム)に対してインデックスを設定する必要があります。
2:インデックスを過剰に設定しない
インデックスは、検索の高速化以外にも、データの挿入(INSERT)、更新(UPDATE)、削除(DELETE)などの処理にも影響を与えます。
インデックスが設定された列にレコードが追加される場合は、同様にインデックスにもレコードを追加する必要が出てきます。これは更新、削除についても同じ。
そのため、インデックスを無駄に設定しまうと、データの変更処理が遅くなってしまう可能性が出てきます。
適切にインデックスを設定するには、データ量や変更頻度、対象データベースの利用状況などを考慮する必要があります。
3:インデックスの種類を適切に選択する
インデックスには、本記事でも説明したプライマリキー以外にも、複合インデックス、全文検索インデックスなど様々な種類があります。
保存されているデータの種類によって、どのインデックスが最も効果を発揮するのか?の答えも変わってきます。
ベテランのエンジニアは、それぞれのインデックスの内容・特徴を把握し、対象のテーブルに対し一番効果的なインデックスを設定したりすることが可能なので、その分パフォーマンスに優れたシステムを開発できるようになります。
また、適切なインデックスを設定することは、検索の高速化だけではなくデータの整合性や検索結果の精度も向上させることができます。
システムエンジニアを目指したい方は
システムエンジニアを目指す方や、IT知識を1から身につけたい方は以下のページをご覧ください。
正直どこから学び始めればよいかわからない。どのように勉強していけば、エンジニアとしてのスキルが磨けるか?が分からない・・・という方は必見です。
システムエンジニア向けに「できるエンジニア」になる方法を1から解説しておりますので、是非ご覧ください。
