
ABAPプログラミングにおいて特徴的な概念の1つが内部テーブルです。内部テーブルには、いくつか種類がありシーンに応じて適切に使い分ける必要があります。
このページでは、「そもそも内部テーブルって何?」という疑問をお持ちの方でも理解できるよう内部テーブルの基本知識から、ソートテーブル・ハッシュテーブルなどの実践的な知識までを網羅的に解説します。
SAPエンジニアを目指す方であれば知っておきたい超基本事項ですので、このページの内容は漏れなく理解しておくようにしましょう。
前提:内部テーブルとは?
内部テーブルとは、プログラム実行時にのみメモリ上に存在するテーブルのことです。
「テーブル」とは、Excelのように行と列が複数存在する表のようなものです。(他の言語の言葉を借りて言えば、二次元配列のようなデータ構造と言えます。)
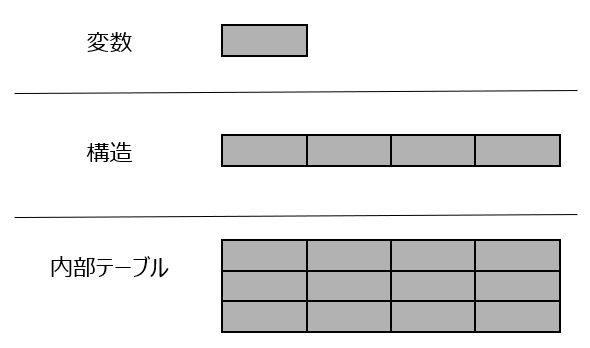
プログラムの実行中にのみ利用する作業用のExcelのようなものだという理解ができればまずはOK!
ABAPの基本「変数」「構造」「内部テーブル」の区別ができていない方は、この機会に以下のページをご覧いただき、データオブジェクトの基本を理解しておきましょう。

内部テーブルの種類
内部テーブルと一口に言っても、使い方や目的によって大きく4つに分類されます。
基本的なプログラムであれば、基本となる「STANDARD TABLE(標準テーブル)」だけを押さえておけばOKです。
ただし、機能が複雑になる場合や、パフォーマンスに優れたプログラミングが求められる場合は、他の種類の内部テーブルの利用も必要になります。
ここでは、1つずつその用途と特徴・構文ルールを分かりやすく解説していきます。
標準テーブル(STANDARD TABLE)
標準テーブルは、その名の通り最も基本となる内部テーブルのこと。
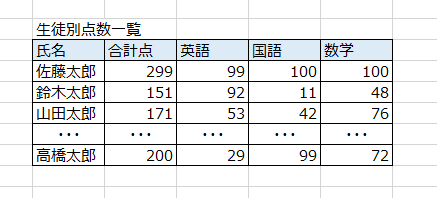
ご覧のように、Excelのような誰がみても理解できるような形でレコードが順不同に存在しています。ABAPエンジニアの方が単に「内部テーブル」と呼ぶ場合は、この「標準テーブル(STANDARD TABLE)」を指す場合がほとんどです。
構文ルール: ~STANDARD TABLE OF~
DATA (内部テーブル名) TYPE STANDARD TABLE OF (参照構造).
変数や構造と同じように内部テーブルの宣言はDATA命令を用いて宣言します。TYPEオプションの後に「STANDARD TABLE OF」の文言を入れて、標準テーブルであることを明示します。
DATA: LT_ZZZ001 TYPE STANDARD TABLE OF ZZZ001, LT_ZZZ002 TYPE TABLE OF ZZZ001.
単に「TABLE OF」というコードで宣言しても標準テーブルとして認識されます。
明確にその内部テーブルが「標準テーブル」であることを示したほうが良い場合は、丁寧に「STANDARD」と明記したほうが良いでしょう。
標準テーブル(STANDARD TABLE)の特徴
標準テーブルは、行数が多くなれば多くなるほど、検索にかかる時間も多くなるということ。簡単に言えば、データ量に比例して検索速度も遅くなるということです。
10件~1000件ほどのレコードを処理する場合には標準テーブル(STANDARD TABLE)の形で宣言すべきですが、レコード数が10000万件以上になる場合は、後述するハッシュテーブルの利用が推奨されます。
内部テーブルはあくまでも作業用のテーブルです。したがって、基本的には処理対象とするデータはできるだけ絞った形で内部テーブルに格納するのが定石です。
ソートテーブル(SORTED TABLE)
ソートテーブルは、その名の通りレコードが並び替えされた状態で格納される内部テーブルのこと。
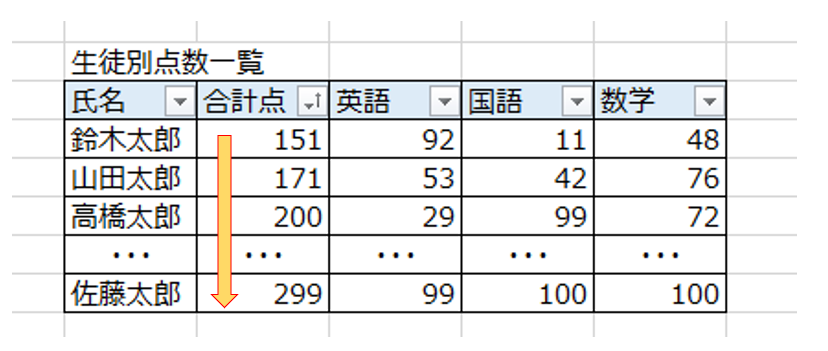
上記の例は、「合計点」を基準に昇順でソートした内部テーブルのイメージです。
構文ルール: ~SORTED TABLE OF~
DATA (内部テーブル名) TYPE SORTED TABLE OF (参照構造) WITH (キー項目).
DATA: SORT_T1 TYPE SORTED TABLE OF BKPF WITH UNIQUE KEY BUKRS, SORT_T2 TYPE SORTED TABLE OF BSEC WITH NON-UNIQUE KEY NAME1 NAME2.
ソートテーブルの場合は、TYPEオプションの後に「SORTED TABLE OF」と続け、最後に「WITH」オプションで並び替えをするキー項目を指定します。
尚、キー項目の指定方法は以下の2種類に分かれます。
DATA:
LT_ZZZ101 TYPE SORTED TABLE OF ZZZ101
WITH NON-UNIQUE KEY A B,
LT_ZZZ102 TYPE SORTED TABLE OF ZZZ102
WITH NON-UNIQUE KEY A B,
LT_ZZZ103 TYPE SORTED TABLE OF ZZZ102
WITH UNIQUE KEY A B C D.
ソートテーブル(SORTED TABLE)の特徴
ソートテーブルでは、レコードを追加する際に並び順が整理されるため、標準テーブル(STANDARD TABLE)と比較して処理スピードが落ちます。
ただし、逆にレコードを検索する際は、事前に並び替えが行われた状態となるため、検索する処理速度が速くなります。
レコードを追加する場合の処理速度
標準テーブル > ソートテーブル
レコードを検索する場合の処理速度
標準テーブル < ソートテーブル
頻繁にレコードを出し入れするような場合は標準テーブル(STANDARD TABLE)が向いていますが、プログラム実行中に何度も参照して利用するような場合は、ソートテーブル(SORTED TABLE)がむいています!
ハッシュテーブル(HASHED TABLE)
ハッシュテーブルは、1つ1つのレコードに対してハッシュ処理がなされているテーブルのことです。
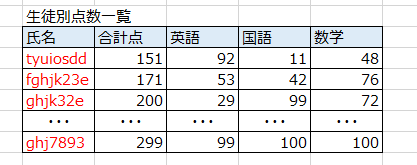
上記の例では、氏名の値が一定の計算ルールに基づき置換されて保存されている状態を表しています。
構文ルール: ~HASHED TABLE OF~
DATA (内部テーブル名) TYPE HASHED TABLE OF (参照構造) WITH UNIQUE KYE (項目名).
ハッシュテーブルを宣言する場合は、TYPEオプションの後に「HASHED TABLE」と続け、最後に「WITH」オプションでキー項目をしてする必要があります。
DATA:
LT_ZZZ201 TYPE HASHED TABLE OF ZZZ201
WITH UNIQUE KEY BUKRS ZZ01.
ハッシュテーブル(HASHED TABLE)の特徴
ハッシュテーブルの特徴は、格納されたレコードを検索するスピードが「データ量に関わらず一定」であるということ。
これが、ハッシュテーブルの最大の特徴です。データ量に関わらず一定、という性質のため、データ量が大きいテーブルを処理する際にハッシュテーブルが採用されます。
例えばデータが1000万件に上るような「ほぼデータベースそのまま」のような処理を行う際にハッシュテーブルを採用するとよいでしょう。
ハッシュテーブルの注意点① キー指定
ハッシュテーブルでは必ずレコードが一意に特定できるようにキーを指定する必要があります。
もし一意でキーを指定しない場合、プログラムの実行中に「ショートダンプ」が発生し、処理が中止されます。
参照したテーブルのキー項目をすべて「WITH UNIQUE KEY」オプションの後ろに指定してあげればOK。
ハッシュテーブルの注意点② 検索時の指定
ハッシュテーブルを検索する際も、①同様にキー項目を全て指定する必要があります。ハッシュ値がキー項目を基準に生成されているためです。
また、上記の理由によりハッシュテーブルから「同時にデータを複数個検索することはできません」。
膨大なレコードの中から、毎回1つのレコードを参照すればOKな場合にハッシュテーブル(HASHED TABLE)を用いると良いでしょう。
レンジテーブル
レンジテーブルはその名の通り「範囲を保持するテーブル」です。
レンジテーブルは、これまでに解説した他の3つの内部テーブルと異なり、実際にすべてのレコードを格納せず、レコードの範囲情報を格納する特殊なテーブルです。
レンジテーブルはこれまで解説してきた内部テーブルとはちょっと様相が異なっており、かつ利用頻度も非常に高いため、以下の記事で詳しく整理して解説いたしました。合わせてご覧ください。

SAP / ABAPを1から学習したい方は
初めてABAPを勉強するのは結構難しいですよね。
でもその悩みを抱えているのは一人じゃありません。全てのABAP使いが同じ道を進んできました。
ABAPをはじめとするプログラミングスキルを武器に、時間と場所に捉われない自由な生き方を目指してみませんか?
あなたの技術、もっと価値ある場所で活かしませんか?
SAPエンジニアのキャリア支援はこちらから↓
No.1 > 外資系・IT業界などハイクラスの転職なら【アクシスコンサルティング】![]()
4人に1人のコンサルタントが選ぶパートナー!
ビッグ4やアクセンチュアへの転職を実現し年収1000万へ。
No.2 > IT・Web転職特化エージェント【レバテックキャリア】![]()
![]() サービス利用者数20万人突破。
サービス利用者数20万人突破。
平均年収アップ率77%であなたの転職成功を保証します。
No.3 > ![]() リクルートエージェント
リクルートエージェント
![]() \転職支援実績NO.1/
\転職支援実績NO.1/
応募が殺到しすぎるが故に・・・非公開にせざるを得ない魅力的な求人が多数!
読者料典 【完全無料】ABAP:学習カリキュラム ←こちらから!