
SAP中級者~上級者向けにプールテーブル/クラスタテーブルとは何か?を3分で解説します。
プールテーブルもクラスタテーブルもどちらもSAPにおける特殊なテーブルの1種。SELECT文における外部結合 / 内部結合が行えない等の制約があるテーブルで、一般的な透過テーブルと分けて理解する必要があります。
このページでは、プールテーブル/クラスタテーブルって何?どういうテーブルなの?透過テーブルと何が違う?という疑問に3分でお答えします。
一段上のABAPエンジニアを目指す方であれば知っておいて損はない重要知識です。是非最後までご覧ください。
【SAP】テーブルには3種類ある
SAPのテーブルは以下のように大きく3つに分類することができます。
これらの違いはざっくり言ってしまうと「データベースへの保存方法」です。
このページの前提となるSAPのデータベースについて初めに補足しておきます。
【前提知識】SAP:データベースインターフェース
SAPでは利用できるデータベースは多岐にわたります。代表的なものをあげると「Microsoft SQL Server」や「Oracle」「HANA」など。その他にもマイナーなデータベースまで幅広く利用することが可能です。
実際はそれぞれのデータベースごとに固有の制約があったり、それぞれで発行すべきSQL文なども微妙に異なったりするのですが、普段我々SAPエンジニアはその差異をあまり意識することはありません。
利用しているデータベースがOracleであれ、 Microsoft SQL Serverであれ、HANAであれ基本的には同じABAP命令で操作することが可能ですし、SE16N:テーブルブラウザでテーブルデータを参照する際も別にデータベースが何か?を気にすることはないのです。
このデータベースごとの差異を吸収しているのが、SAPにおけるデータベースインターフェースという仕組みです。データベースインターフェースは、SAPのアプリケーションとデータベースの中間層に位置する「翻訳機」のような役割を果たします。
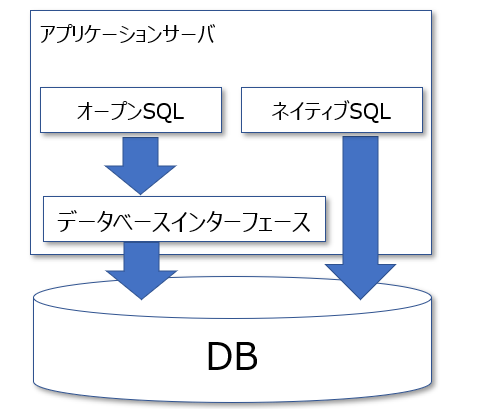
もし、こデータベースインターフェースが存在しなかったら、利用しているデータベースに応じてABAP命令を微妙に使い分けたり、SE16N:テーブルブラウザでテーブルデータを参照する際にデータの見え方が微妙に異なっていたりしてしまいます。
つまり、まずここで押さえておきたい内容は「SAP上で見えているテーブルの形と、実際にデータベース上で保存されているテーブルの形は微妙に異なる場合がある」ということ。この前提知識がないと、プールテーブル/クラスタテーブルを正確に理解することは難しいでしょう。
透過テーブル
最も一般的なテーブルは透過テーブルです。アドオンテーブルやほとんどのSAP標準テーブルは透過テーブルに該当します。
透過テーブルは、SE11:ABAPディクショナリ上で登録した構造と同じ構造(SAPで見たままの構造)でデータベース上に保存されるテーブルのこと。
初心者研修などで「透過テーブルって何?」と思う方も多いかと思いますが、SAPでは普通のテーブルのことを透過テーブルと呼ぶんだな・・・と理解しておけばまずはOKです。
一方でプールテーブルとクラスタテーブルはデータベース上での保存のされ方が、 SE11:ABAPディクショナリ で見た時と異なって保存されます。ここからは本題「プールテーブルとクラスタテーブルとは何か」から解説していきます。
プールテーブルとは
プールテーブルは、テーブルプールに割り当てられたテーブル(テーブルプールに保存されるテーブル)のことです。
どういうこと?となりますよね?順を追って説明していきます。
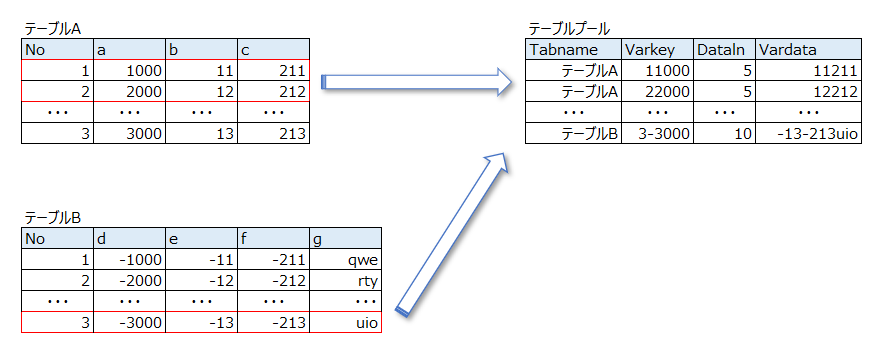
プールテーブルの保存方式
以下テーブルAとテーブルBはプールテーブルをSE16N:テーブルブラウザで参照した際のイメージです。SAPから見た際のデータの持ち方は、保持透過テーブルと何ら変わりがありません。

もう一度説明をしますが、もしこれが透過テーブルの場合であればこの形のままデータベース上に保存されます。ですが、プールテーブルの場合は、実はデータベース上では異なる形で登録されます。
プールテーブルは簡単に言えば複数のテーブルが1つのテーブルにまとまって登録されているだけ。テーブルプールという1つのテーブル上に保存されるのがプールテーブルです。
少しややこしいのですが、プールテーブルが保存されている先がテーブルプールです。
テーブルプールの構造は以下のように決まっています。
テーブルプールの格納イメージ
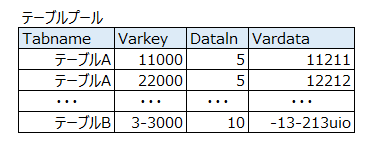
テーブルプールは、ご覧のように一番左の項目に「テーブル名」を持っています。
つまり、保存のされ方を図示すると以下のようになります。
なんとなく「1つのテーブルに保存」の意味が分かるかと思います。何度も繰り返しますがプールテーブルは、テーブルプールにまとめて格納されるのです。
テーブルプールの構造
テーブルプールは4つの項目を持ちます。詳細まで把握している必要はありませんが、参考として覚えておくと役立つかもしれません。
先ほどのテーブルプールの画像と合わせて学んでみてください。
| 項目 | データ型 | 説明 |
| Tabname | CHAR(10) | テーブルの名称が入ります |
| Varkey | CHAR (1~110) | プールテーブルの全てのキー項目が文字列として入ります |
| Dataln | INT2(5) | ↓のデータの長さ |
| Vardata | RAW (n) | プールテーブルのキー項目以外の全てのデータが入ります |
クラスタテーブル
実はプールテーブルの概念を理解してしまえば、クラスタテーブルの理解は早いです。クラスタテーブルも「1つのテーブル」に格納されているという意味で全く同じです。
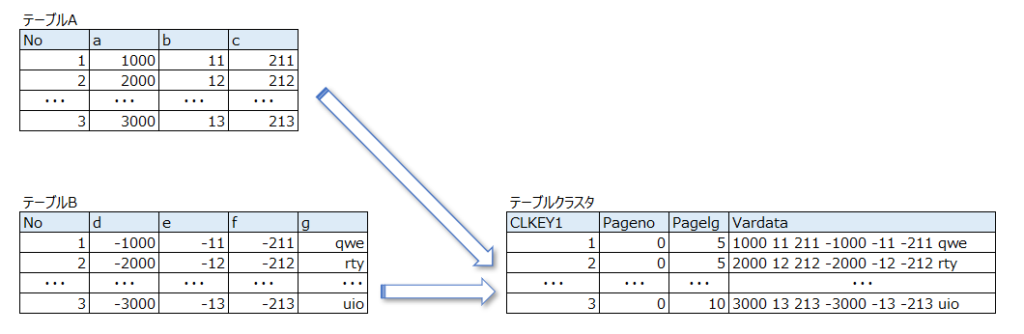
クラスタテーブルの場合は、保存される先のテーブルをテーブルクラスタと呼びます。
単語の使い分けが難しいので、しっかりと整理しておきましょう。
プールテーブルとクラスタテーブルの違い
では、プールテーブルとクラスタテーブルは何が違うのでしょうか?答えは「クラスタテーブルは主要キーで内部結合されている」ということです。
プールテーブルでは、データがそのまま格納されているのに対して、クラスタテーブルは「主要キーで内部結合された状態」で保存されているということです。先ほどのテーブルをクラスタテーブルバージョンで表すと以下のようになります。
テーブルクラスタの構造
| 項目 | データ型 | 説明 |
| CLKEYn | * | n 番目のキー項目を表す 例)CLKEY1、CLKEY2・・ |
| Pageno | INT2(5) | 継続レコードの番号 |
| Timestamp | CHAR(14) | タイムスタンプ |
| Pagelg | INT2(5) | ↓のデータの長さ |
| Vardata | RAW (n) | プールテーブルのキー項目以外の全てのデータが入ります |
テーブルプールと違い、項目数は固定ではなくなります。これは、キー項目を何個にするかの指定によって異なるためです。
継続レコードとは?
上記表中青線ハイライト部分の「継続レコード」について解説します。継続レコードとは「何番目のレコードか?」という情報を持つ項目になります。
キー項目以外の項目、すなわち「Verdata」の最大長は有限です。※最大長は、データベースによって異なります。
テーブルプールでは、内部結合を行わないそのままのデータであるため、最大長を越えるデータが生まれることはありませんが、テーブルクラスタでは内部結合の結果次第で項目数が増加するため、最大長を越える場合があります。
その際、継続レコード項目で1,2,3と項番を振ることによって最大長越えのキー項目に対応をしています。項番は0から始まる昇順で採番されます。
プールテーブルとクラスタテーブルの注意点
プールテーブル / クラスタテーブル利用時の注意点を3点ご説明しておきます。
注意点①:NativeSQLが利用できない
NativeSQLとは、データベースを直接読みに行くSQLのことを指します。
データベース上では、上記で解説してきたようにキー項目以外は全て文字列で結合されている状態ので、データベース上を直接読むNativeSQLは利用できません。OpenSQLは利用可能です。
OpenSQLとNativeSQLの違いはこちらで詳しく解説しております。

注意点②:キー項目以外を抽出条件に入れてはいけない
SELECT文のWHERE句でキー項目以外の項目を抽出条件に入れると著しくパフォーマンスが悪化します。上記で述べた通り、キー項目以外の項目は文字列で結合されている状態です。
したがって、それらを抽出条件に入れてしまうと、結合を分解し処理することになるので、その分パフォーマンスが悪化します。
SELECT文で内部結合・外部結合ができない
内部結合・外部結合はできません。これが一番重要な内容です。
プールテーブル / クラスタテーブルは特殊な形で保存されているデータであるため、OpenSQLを利用しても結合操作が行えないという点に注意しましょう。
結論、プールテーブル/クラスタテーブルは内部結合・外部結合ができない、とだけ覚えておけばあまり困ることはありません。
SAP/ABAPを1から勉強したい方は
初めてABAPを勉強するのは結構難しいですよね。
でもその悩みを抱えているのは一人じゃありません。全てのABAP使いが同じ道を進んできました。
ABAPをはじめとするプログラミングスキルを武器に、時間と場所に捉われない自由な生き方を目指してみませんか?
あなたの技術、もっと価値ある場所で活かしませんか?
SAPエンジニアのキャリア支援はこちらから↓
No.1 > 外資系・IT業界などハイクラスの転職なら【アクシスコンサルティング】![]()
4人に1人のコンサルタントが選ぶパートナー!
ビッグ4やアクセンチュアへの転職を実現し年収1000万へ。
No.2 > IT・Web転職特化エージェント【レバテックキャリア】![]()
![]() サービス利用者数20万人突破。
サービス利用者数20万人突破。
平均年収アップ率77%であなたの転職成功を保証します。
No.3 > ![]() リクルートエージェント
リクルートエージェント
![]() \転職支援実績NO.1/
\転職支援実績NO.1/
応募が殺到しすぎるが故に・・・非公開にせざるを得ない魅力的な求人が多数!
読者料典 【完全無料】ABAP:学習カリキュラム ←こちらから!